Table of Contents
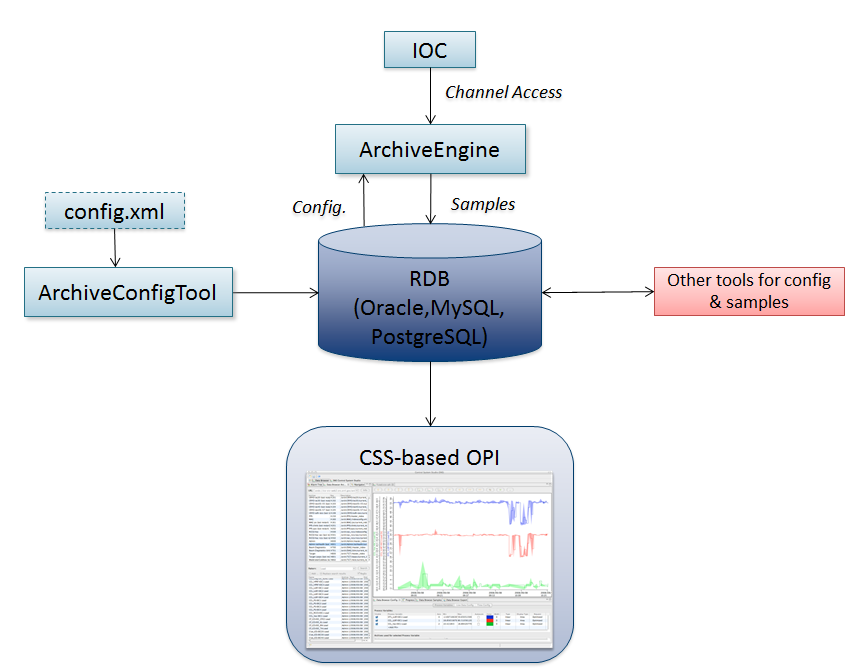
One part of CSS is the Archive System, specifically the “Best Ever Archive Toolset, yet (BEAUTY)” that was developed as a replacement for the Channel Archiver. An Archive Engine takes PV data samples from a front-end computer, for example from EPICS IOCs via Channel Access, and places them in some data storage, see Figure 11.1, “Archive System Overview”. Archive client programs then access historic data samples in that storage.
As described here, the storage is a Relational Database (RDB) like MySQL, Oracle or PostgreSQL. Both the historic data of PVs and the Archive Engine configuration are stored in the same relational database. The engine configuration can be imported from an XML file format into the database, or it can be exported from the database back into an XML file format for editing. The archive engine uses a pluggable implementation for its configuration and data storage as described in Chapter 32, Archive Tools - org.csstudio.archive.engine and related, so it is fundamentally possible to use the archive engine with different storage for the configuration and data, but in the following examples we concentrate on an RDB-based setup.
Typical setups will include more than one Archive Engine, for example one sample engine per subsystem. In principle, data providers other than archive engines can also write samples to the storage. The CSS Data Browser is a generic client program for looking at archived data, but fundamentally any program that has access to a relational database can be used to create reports. A typical application might be JSP-based web reports of data.
There are two integration points with the legacy Channel Archiver:
The ArchiveConfigTool tool can import existing archive engine configuration files into the RDB because the
XML file format is compatible with the Channel Archiver.
The Data Browser is capable of reading data from the relational database as well as from the Channel Archiver's
XML-RPC-based data server, thereby allowing nearly transparent access to both “old” and “new”
data.
Before using the archive tools, you need to create the required table structure in your RDB. Currently MySQL, Oracle and PostgreSQL are supported, see also Chapter 10, Relational Database (RDB).
The commands for creating the RDB table structures are in files in the dbd sub-directory
of the plugin org.csstudio.archive.rdb.
Basic RDB administration skills will be required because you need to create the table structure by using one of these files,
and will probably also need to create two accounts: One account for the archive engines that has write access to the tables,
and another read-only account for archive clients like the CSS Data Browser to read archived data.
The RDB tables for the different database dialects are very similar with the exception of the
TIMESTAMP used to store the time stamps of samples.
While the Oracle time stamp data type already offers nanosecond detail,
the MySQL and PostgreSQL data types of the same name only cover seconds.
The MySQL tables therefore have an added nanosecs column for this purpose.
There are a few more differences in the SQL dialects, but the Archive Engine and Data Browser
auto-configure based on the database URL.
The setup for MySQL might be the easiest at least for development and testing, but it has limitations.
All samples for all channels are written to one sample table. By default, MySQL table sizes are limited to 4GB
(See MySQL show table status command, column “Max_data_length”).
While this can be adjusted, I believe there is still a limit of 4G rows (=samples).
Furthermore, while it will be almost trivial to enter something like
DELETE FROM sample WHERE smpl_time < ...
to delete older samples, this will either not free up any space or require an added OPTIMIZE rebuild, which takes a very long time.
For PostgreSQL, the table size limit at this time seems to be much higher at 32TB, with no additional row count limit.
Performance of the sample table that holds archived samples is reduced by about 50%
when adding constraints. The dbd file for PostgreSQL includes constraints to allow the RDB
to assert referential data integrity, but if you trust the Archive Engine code to only write correct
samples to the RDB, performance can be gained by disabling the sample table constraints.
One reason for using Oracle lies in its support for partitioning.
While the sample sample appears as one table,
it can be spread over several table partitions based on the sample time and channel name.
Spreading by channel name might improve performance because several channels can be written
in parallel to different disk locations. Partitioning by time allows quick removal of older samples.
In addition, for Oracle the archive data readout implementation used by the Data Browser
(plugin org.csstudio.archivereader.rdb)
supports a stored procedure for server-side data reduction which is not available for MySQL.
Whatever database you use, in the end you need to provide all CSS archive tools with the following configuration information as elaborated in the section called “RDB URLs and Schemata”:
- URL
- User name
- Password
- Schema
For the Archive Engine and Archive Config Tool, you need to provide the user name and password of an RDB account that has write access to the archive tables. For the Data Browser or other tools that read data, a read-only account is sufficient. See Chapter 6, Hierarchical Preferences for details on how to provide these RDB settings for the archive plugins. The command-line tools will also accept these parameters on the command-line.
The Archive Engine is the central sampling tool that reads values from PVs and writes them to the archive data storage. It is implemented as an Eclipse product. You will probably also want to build ArchiveConfigTool, the tool used to import engine configuration files into the relational database. They are defined in these product files:
org.csstudio.archive.engine/ArchiveEngine.product org.csstudio.archive.config.rdb/ArchiveConfigTool.product
For first tests, you can run both tools from within the Eclipse IDE as described in Chapter 4, Compiling, Running, Debugging CSS, the section called “Using the Eclipse IDE”, but note that you will have to provide command-line arguments to them. After first tests are successful, you can export them from the IDE as described in the same section. Finally, you will need one of the CSS end-user products that includes the Data Browser to look at the archived data, but for now we concentrate on the tools needed to collect data.
Each sample engine configuration identified by a name, for example “WaterSystem”. Inside the RDB the configuration is actually identified by a unique numeric ID, but most end user tools only see the name of the configuration.
Each archive engine configuration is comprised of groups. An engine configuration has at least one group, maybe more, and channels are then added to these groups. Groups are not hierarchical: There are no sub-groups within groups, only one list of groups.
Groups are primarily used to organize the configuration. For example, a “WaterSystem” sample engine configuration might have groups “WestSector”, “MainBuilding” etc. to hold the channels for the respective section of the water system. Note that this arrangement of channels into groups is not visible to end users of the data! The separation of channels into groups inside the sample engine configuration is mostly meant for the engineers who maintain the sample engine configuration, grouping the channels by location along the machine, but associated front-end computer, or by functionality.
There is one functional aspects of groups: Archiving of all channels in a group can be enabled or disabled based on one channel in the group. When placing all channels of a power supply in a group, this feature can be used to suppress archiving of noise while the power supply is off by using a channel that indicates whether the power supply is on or off to enable the archive channel group.
A channel in the archive system is basically the data provided by one Process Variable. A channel is identified by its name, which has to be a valid PV name for the control system, a PV that you can also read with other control system tools. The samples stored for the channel include not only the value, for example a number, but also the time stamp, status/severity and meta data like engineering units and display ranges. The time stamp, status/severity and value are stored with each sample. The meta data is only stored once at startup of the archive engine because the original implementation for EPICS did not offer an efficient way to monitor for changes in the meta data.
When a channel sends a new value to the archive engine is somewhat outside of the
control of the archive engine. The software on the front end computer controls this.
For EPICS record, the SCAN field in combination with the ADEL field
of analog records determines when a new value is sent to the archive engine.
The meta data for a channel is similarly controlled by the front end device that
provides the data. For EPICS records, the EGU, HOPR and other fields
have to be used to configure these.
The RDB configuration allows for multiple sample engines. Each sample engine has one or more groups of channels, and each group has one or more channels. A channel, however, can only be archived once. It is illegal to list a channel in more than one group or under more than one sample engine.
The archive engine supports several sample modes, i.e. ways in which it decides what samples should be written to the archive data store. As just mentioned in the section called “Channels”, the front-end computer decides which updates to send to the archive engine. In an ideal world, every such change would be meaningful and there were infinite resources (CPU power, disk space, network bandwidth) to store every change until eternity. In reality, it is often better to store fewer samples.
The archive engine supports the following sample modes by which it collects samples from a channel. Refer to the section called “Archive Config Tool” for an example of how these sample modes are specified in the XML format that can be used to configure an archive engine.
In monitored mode, each received sample is written to the store. With a perfectly
configured data source, for example an EPICS ADEL that only passes
significant changes to the archive engine, this mode is ideal:
Significant changes in value are written to the archive, while noise in the signal
is suppressed to minimize wasted resources.
When configuring a monitored channel, the estimated time period between changes needs to be configured to allow the archive engine to reserve a suitable memory buffer where it stores received samples until they are written to the storage.
This mode is also monitored, but adding another value change threshold filter. Ideally, the front-end computer already performs the thresholding, so only significant changes are sent over the network to the archive engine. In some cases, however, this is not possible, and for those cases the archive engine itself can check for changes in the value, writing only samples that differ from the last written sample by at least some configurable margin.
As with plain monitored channels, the estimated time period between changes needs to be configured.
In scanned mode, the archive engine still receives each update from the data source, but it only writes the most recent sample at periodic times, for example once every 5 minutes.
For a scanned channel you configure the period at which the archive engine should check the channel for its current value.
This mode is a compromise. If a channel has no significant change for hours, why should the uninteresting changes fill disk space every 5 minutes? On the other hand, if an important even happens that produces a brief “blip” in the data, the archived data is likely to miss it when only storing a value every 5 minutes.
This mode was created for channels which do not have a good dead-band configuration, where using the monitored mode would add too many samples to the archive. Periodic sampling is clearly imperfect, but sometimes a workable compromise.
Samples obtained by the various samples modes are not immediately written to storage, for example the RDB, because writing each individual sample right away would be too slow. Instead, samples are initially kept in memory, then written to storage in bulk. By default, this write period is 30 seconds.
The period configured for scanned channels or the estimated change period for monitored channels is used to allocate the in-memory buffer that the engine uses to collect samples between writes. The in-memory buffer is a ring buffer that is written each write period. If a monitored channel sends many more samples than configured via the estimated update period of a channel, the archive engine sample buffer for that channel will overrun older in-memory samples for that channel. The archive engine actually uses a buffer reserve to allocate a slightly bigger in-memory buffer to avoid such overruns:
buffer_size = write_period / scan_period * buffer_reserve
The default buffer reserve is 2. With the default write period of 30 seconds, a channel with an estimated change period of 2 seconds would thus expect to need to buffer 15 samples between writes to storage, but the the actual buffer size would be 30 to prevent ring buffer overwrites during times where writing to storage is slightly delayed, or a few more samples are received than originally expected. The in-memory buffer still has a fixed size, it will not grow when more samples are received to keep a constant memory footprint for the archive engine.
When writing accumulated samples for all channels to storage, i.e. by default every 30 seconds, the samples are written in batches. For RDB-based storage, the JDBC statements are batched to reduce the number of individual commits to the RDB. The default batch size is 500.
When viewing archived data, the time stamps of historic samples are obviously quite important. The Archive Engine simply receives time-stamped data from front end computers and has no way to determine if those time stamps are correct. It enforces, however, a few basic rules:
- Zero time stamps: Time stamps with zero seconds, for example EPICS time stamps with zero seconds since the EPICS epoch of 1970, are ignored.
- Time stamps that go back-in-time, i.e. time stamps that are before samples that have already been inserted into the archive, are ignored.
- Futuristic time stamps, that is time stamps that are too far ahead of the clock of the host that is executing the archive engine, are ignored. By default, this ignored future is 1 day.
The configuration for all archive engines resides in the RDB, which allows you to modify it in various ways. Note, however, that running archive engines are not notified of configuration changes in the RDB because there is currently no convenient mechanism for them to learn about such changes. You must manually re-start all affected archive engines after modifying their configuration!
It is possible to modify an archive engine configuration via direct SQL manipulation, for example from an SQL shell:
SELECT * FROM smpl_eng;
INSERT INTO smpl_eng(name, descr, url)
VALUES ('demo', 'Example Engine',
'http://somehost:4812');
This clearly requires some familiarity with the RDB table layout, see the section called “Relational Database Setup”. For operations like renaming a channel or bulk changes this can be the most convenient procedure.
The ArchiveConfigTool can export existing archive engine configurations
from the RDB into an XML file format, or import such XML files into the RDB.
The XML file format is compatible with the one used by the Channel Archiver,
allowing the import of existing archive engine configurations.
The xml directory in the plugin
org.csstudio.archive.config.rdb contains a commented
example configuration file:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<!-- Example for XML configuration file syntax -->
<engineconfig>
<!-- Engine can have one or more groups
Each group has a name and one or more channels
-->
<group>
<name>NorthSectorVacuum</name>
<!-- Each channel has a name and
a sample period (or expected change period).
The period is either in seconds or in HH:MM:SS format.
It is either using the 'monitor' or 'scan' sample mode.
-->
<channel>
<name>NSV:P1</name>
<period>1.0</period><monitor/>
</channel>
<!-- Example for a monitor with engine-enforced
value change threshold of 2.5
-->
<channel>
<name>NSV:P2</name>
<period>1.0</period>
<monitor>2.5</monitor>
</channel>
<!-- Channel that is scanned every 10 minutes-->
<channel>
<name>NSV:Enable</name>
<period>00:10:00</period><scan/>
<enable/>
</channel>
<!-- Channel that enables sampling of this group -->
<channel>
<name>NSV:Enable</name>
<period>1.0</period><monitor/>
<enable/>
</channel>
</group>
<!-- Other Group -->
<group>
<name>SouthSectorVacuum</name>
<channel>
<name>SSV:P1</name>
<period>1.0</period><monitor/>
</channel>
</group>
</engineconfig>
The ArchiveConfigTool offers command-line help similar to this:
-help : show help -engine my_engine : Engine Name -config my_config.xml : XML Engine config file -export : export configuration as XML -import : import configuration from XML -delete_config : Delete existing engine config -description 'My Engine' : Engine Description -host my.host.org : Engine Host -port 4812 : Engine Port -replace_engine : Replace existing engine config, or stop? -steal_channels : Steal channels from other engine -rdb_url jdbc:... : RDB URL -rdb_user user : RDB User -rdb_password password : RDB Password -rdb_schema schema : RDB schema (table prefix), ending in '.'
To export an existing engine configuration into an XML file, use
ArchiveConfigTool -engine my_engine -config my_config.xml -export
In addition, the RDB connection parameters might have to be supplied unless
they are built into the tool or provided via a -pluginCustomization
argument.
To import a configuration from an XML file into the RDB, use
ArchiveConfigTool -engine my_engine -config my_config.xml -import\ -host my.host.org -port 4812
The host name specifies the host on which the engine is supposed to execute, and the port number under which is runs its web server. The configuration file could be the edited result of a previous export, or have been created by other means.
The archive config tool is cautious about disturbing existing configurations.
By default it will stop when there is already a configuration in the RDB for the
same sample engine name unless the -replace_engine option is provided,
in which case an existing configuration for that engine name will be deleted before
importing the XML file.
Similarly, the config tool will ignore channel names that are already handled by
a different engine configuration, unless the -steal_channels option
is provided to instruct the tool to move such channels from the archive engine that
previously handled the channels.
The ArchiveEngine is a headless RCP application that
reads a sample engine configuration, connects to the control system channels
listed in the configuration, and writes received samples to the archive data
store.
It supports these command-line arguments:
-help : Display Help -port 4812 : HTTP server port -engine demo_engine : Engine config name -data /home/fred/Workspace : Eclipse workspace location -pluginCustomization /path/to/mysettings.ini: Eclipse plugin defaults
The -pluginCustomization parameter can be used to provide
settings for the RDB connection, to configure the logging, and to provide
settings for access to the control system, for example EPICS Channel Access
network preferences.
The -engine parameter selects the sample engine configuration.
In principle, that engine configuration already includes the URL of the
engine web server, but an additional -port parameter is required
for two reasons: First, this allows the engine to start a web server which
can be used to monitor engine operation as soon as possible, for example while
the engine it trying to connect to an RDB. Secondly, the engine will compare the
provided port number with the port number of the URL in its configuration.
This is means as a basic constistency check that helps avoid running archive engines
with the wrong configuration.
Each sample engine has a built-in web server for status information and basic remote control of the engine. When starting the engine on a host, the port number for this HTTPD must be provided. The sample engine URL configured in the RDB should match the format
http://<host>:<port>/main
The engine will compare the port number from the URL with the port number provided as a command-line argument.
The engine web server provides several web pages, mostly linked
from the .../main URL, that allow you to see:
- Is the engine running? Since when?
- Are all channels connected? Which are disconnected?
- What is the last data that a channel has received? What is the last sample that was written to the storage?
In case of problems, the last item is usually helpful to determine: Does the front end computer send correct time stamps? Does the data change to qualify for writing a new sample to the storage?
Note that the engine only serves a blank
page at its root URL. For example, accessing http://localhost:4813
will result in an empty page. You have to start browsing at http://localhost:4813/main.
Starting at .../main, one can drill down to the status of groups and individual channels.
A few engine web pages are not accessible by following web browser links because they affect the engine operation. This is meant to prevent a web-crawling program to accidentally stop the engine.
Other Engine URLs
http://<host>:<port>/stop- Invoke this URL to stop the engine gracefully, i.e.
to ask the engine to write a final
Archive_Offsample to each channel, then quit. http://<host>:<port>/restart- Invoke this URL to trigger a running restart of the engine. The engine will stop sampling, read its configuration, then start again. Invoking this URL is required after changes to the configuration of an archive engine.
http://<host>:<port>/reset- Invoke this URL to reset engine statistics, for example the average write time displayed on the main page of the engine.
http://<host>:<port>/environment- Invoke this URL to display engine environment settings which might be useful when trying to debug a problem.
The archive engine tries to write all samples with their original time stamp as received from the Channel Access server. Each unique sample only needs to be written once. The underlying storage may in fact prohibit attempts to write a sample multiple times, or only allow append operations for samples with new time stamps, refusing insertion of samples with previous time stamps. This may result in occasional messages for channels that seldom change, combined with archive engine restarts or network issues.
For example, assume a a channel has not changed since 2013/10/29 08:00. At 09:00, the archive engine is stopped, writing an “Archive Off” value for the channel. At 10:00, the archive engine is restarted. After each start, it will write the current value of each sample. If that is not possible with the actual time stamp of the received sample, because that sample was already written at 08:00 in this example, plus there is already another sample at 09:00 for this channel, the engine will write the sample with the current host clock time, i.e. 10:00. You will then see occasional messages for this channel if its actual value does not change:
WARNING ... - SomeChannelName skips back-in-time: last: 2013/10/29 10:00 3 new : 2013/10/29 08:00 3
This warning can usually be ignored, since no data is lost at all.
The following type of message indicates that the per-channel buffer, used by the engine to keep samples in memory between periodic writes to storage, has been overrun:
WARNING ... - SomeChannelName: 3 overruns
As elaborated in the section called “Writing Samples to Storage”, the size of this buffer depends on the expected update period of a monitored channel, with an added reserve to allow for occasional delays in RDB write performance.
If the warning results from a wrong estimate of expected channel updates, correct the update period estimate. If the warning results from excessive delays when writing to the RDB, try to fix RDB speed issues. Finally, the warning can be ignored if you configured the channel on purpose with an expected update period of say one second, because you intentionally want to suppress occasional bursts of updates, and prefer to preserve storage space.
At the SNS, a JSP-based collection of reports can display graphs of the archive system performance, for example: Which archive engine wrote how many samples to the archive over the last hour? It also includes a web-based editor for the alarm system configuration.
This reporting package, however, is currently part of a bigger, more SNS-specific reporting package. Contact Kay Kasemir if you are interested in collaborating on a more portable version of these reports.
The CSS Data Browser uses the plugin
org.csstudio.archive.reader
to access archived data in general.
The plugin
org.csstudio.archive.reader.rdb
provides access to data stored in an RDB
written by the archive engine described in this chapter,
i.e. it implements reading from URLs of the form
jdbc:.....
For a successful retrieval, you need the following:
- Include
org.csstudio.archive.reader.rdbin your CSS product. - Configure it with the correct (read-only) RDB user and password.
- Configure the Data browser to use URLs like
jdbc:mysql://localhost/archiveto read from the archive.